



- Joined
- 31.10.19
- Messages
- 1,405
- Reaction score
- 4,700
- Points
- 113
Israeli researchers from the Offensive AI Lab have published a paper describing a method for reconstructing text from intercepted messages from AI-chatbots. We will discuss how this attack works and how dangerous it's in reality.
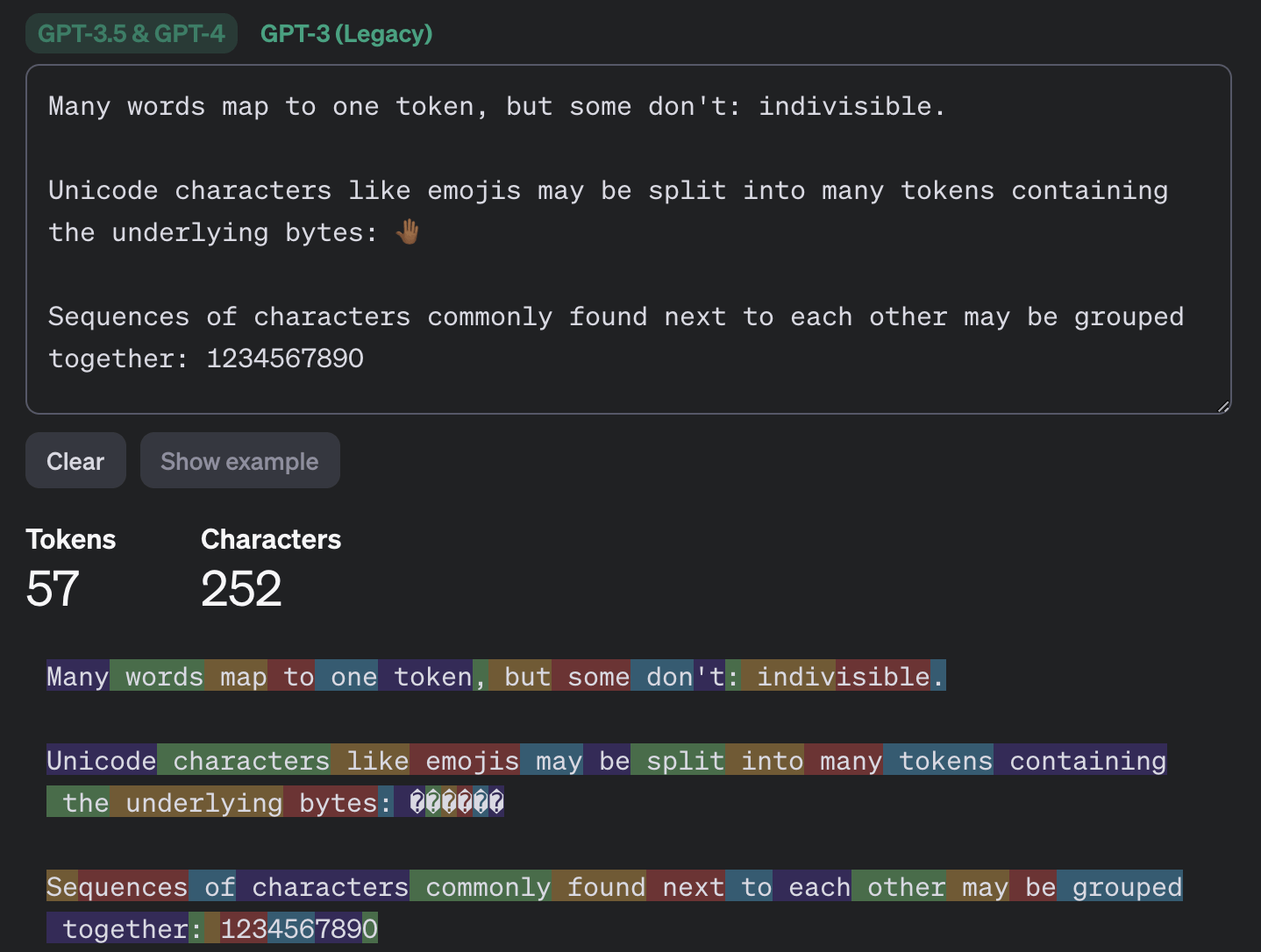
Of course, chatbots send messages in encrypted form. However, in the implementation of both large language models (LLMs) themselves and chatbots based on them, there are several features that significantly reduce the effectiveness of encryption. Together these features allow for a so-called side-channel attack where the content of the message can be reconstructed based on various accompanying data. To understand what happens during this attack we need to delve slightly into the details of LLM mechanics and chatbots. The first thing to know: large language models operate not with individual characters or words but with so-called tokens - a kind of semantic units of text. The OpenAI website has a page called "Tokenizer" that helps understand how this works.
The second feature important for this attack is something you may have noticed when interacting with chatbots: they send responses not in large chunks but gradually - similar to how a person would type it out. However, unlike a human LLMs don't write with individual characters but with tokens. Therefore the chatbot sends generated tokens in real-time, one after another. Most chatbots operate in this manner with the exception of Google Gemini which is not vulnerable to this attack. The third feature is that at the time of the research publication most existing chatbots didn't use compression, encoding or padding before encrypting messages (padding being a method to increase cryptographic strength by adding redundant data to the useful message to reduce predictability). Utilizing these features makes a side-channel attack possible. While intercepted messages from a chatbot cannot be decrypted useful data can be extracted from them - specifically the length of each token sent by the chatbot. The attacker ends up with a sequence resembling a game of "Hangman" on steroids, not for a single word but for an entire phrase: the exact content of what is encrypted is unknown but the lengths of individual token words are known.
This results in a certain text where the token lengths correspond to those in the original message. However, the specific words may be selected with varying degrees of success. It should be noted that a complete match to the original message is quite rare - usually some words are not guessed correctly. In a successful case the reconstructed text looks something like this:

In this example the text was successfully reconstructed adequately. In an unsuccessful case the recreated text may have little - or even nothing - in common with the original. For example, such results are possible:

In this example the guessing was not very accurate. Or even results like these:

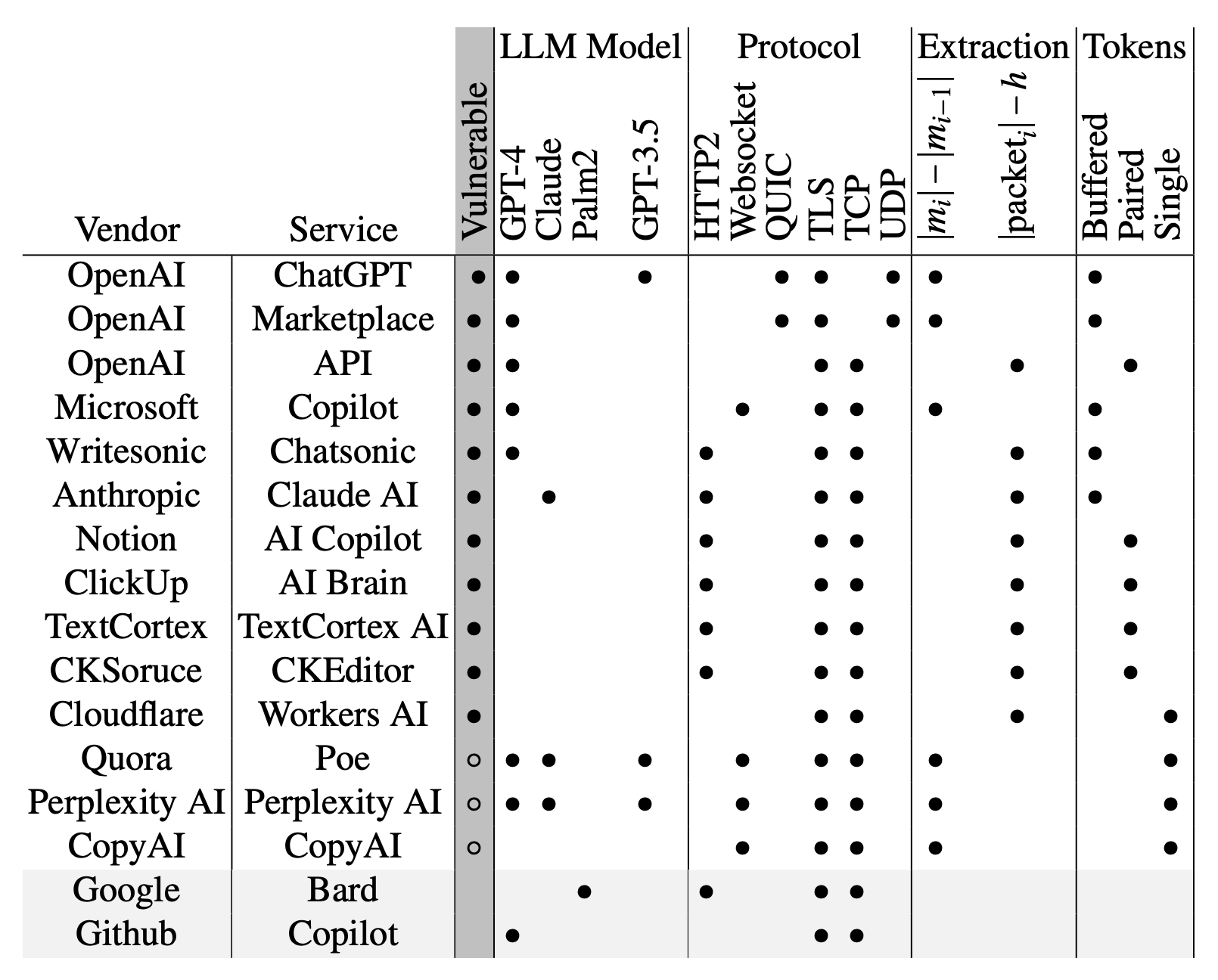
In total, the researchers examined about fifteen existing AI-based chatbots and found most of them vulnerable to this attack - the exceptions being Google Gemini (formerly Bard) and GitHub Copilot (not to be confused with Microsoft Copilot).

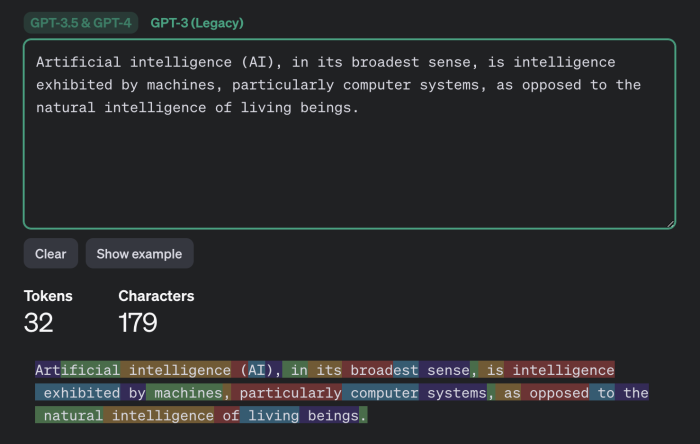
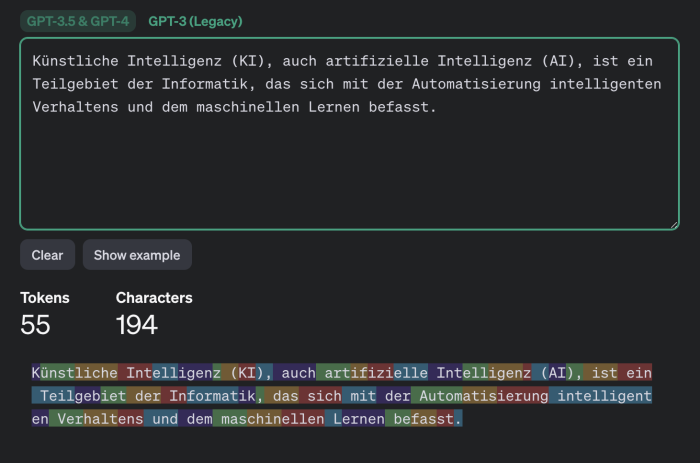
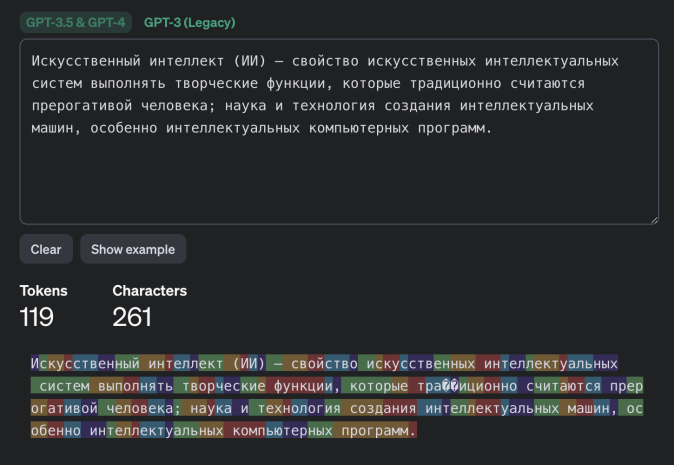
How important such semantic nuances are is for each individual to decide. However, it is worth noting separately that using this method it will likely not be possible to reliably guess factual details (names, numerical values, dates, addresses, contact information and other truly important information). Furthermore, the attack has another limitation that the researchers do not mention: the success of text reconstruction heavily depends on the language in which the intercepted messages were written. The tokenization process operates differently for different languages. For the English language where the effectiveness of this attack was demonstrated, tokens are typically very long - usually equivalent to entire words. Therefore, tokenizing text in English produces distinct patterns making text reconstruction relatively easy. All other languages are much less convenient for this purpose. Even for languages closely related to English in the Germanic and Romance groups the average token length is one and a half to two times shorter, and for Russian it's even two and a half times shorter: a typical "Russian token" is only a couple of characters long likely rendering the attack ineffective. Texts in different languages are tokenized differently. While the attack works for the English language it may not be effective for texts in other languages.
At least two AI-chatbot developers: Cloudflare and OpenAI have already responded to the publication of the research and started using the mentioned padding method which is specifically designed to counteract this type of attack. Presumably, other AI-chatbot developers will soon follow suit and in the future interactions with chatbots will likely be protected from this attack.
What information can be extracted from intercepted messages from AI-based chatbots?
Of course, chatbots send messages in encrypted form. However, in the implementation of both large language models (LLMs) themselves and chatbots based on them, there are several features that significantly reduce the effectiveness of encryption. Together these features allow for a so-called side-channel attack where the content of the message can be reconstructed based on various accompanying data. To understand what happens during this attack we need to delve slightly into the details of LLM mechanics and chatbots. The first thing to know: large language models operate not with individual characters or words but with so-called tokens - a kind of semantic units of text. The OpenAI website has a page called "Tokenizer" that helps understand how this works.
This example demonstrates how text tokenization works with GPT-3.5 and GPT-4 models:
The second feature important for this attack is something you may have noticed when interacting with chatbots: they send responses not in large chunks but gradually - similar to how a person would type it out. However, unlike a human LLMs don't write with individual characters but with tokens. Therefore the chatbot sends generated tokens in real-time, one after another. Most chatbots operate in this manner with the exception of Google Gemini which is not vulnerable to this attack. The third feature is that at the time of the research publication most existing chatbots didn't use compression, encoding or padding before encrypting messages (padding being a method to increase cryptographic strength by adding redundant data to the useful message to reduce predictability). Utilizing these features makes a side-channel attack possible. While intercepted messages from a chatbot cannot be decrypted useful data can be extracted from them - specifically the length of each token sent by the chatbot. The attacker ends up with a sequence resembling a game of "Hangman" on steroids, not for a single word but for an entire phrase: the exact content of what is encrypted is unknown but the lengths of individual token words are known.
How the extracted information can be used to reconstruct the message?
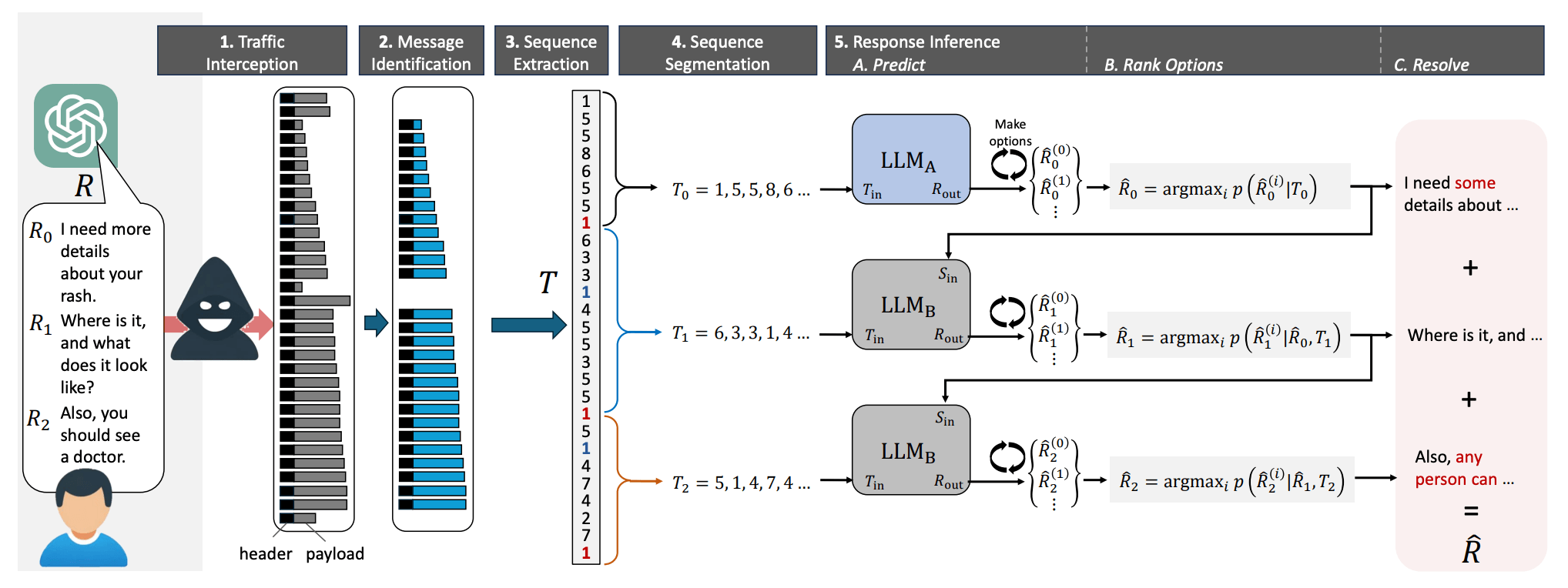
Next, all that remains is to guess which words are hidden behind the "empty cells" - the tokens. And you won't believe who is very good at games of this kind: of course, it's large language models (LLMs)! This is their direct purpose, in fact - to guess appropriate words. So, for further text reconstruction of the original message from the obtained sequence of token lengths researchers used LLMs. More precisely, two LLMs: another idea of the researchers was that initial messages in conversations with chatbots are almost always templated and easier to guess, especially by training the model on an array of introductory messages generated by popular language models. Therefore, the first model reconstructs the introductory messages and passes them to the second model which handles the rest of the conversation text.The general scheme of the attack described in this post looks like this:
This results in a certain text where the token lengths correspond to those in the original message. However, the specific words may be selected with varying degrees of success. It should be noted that a complete match to the original message is quite rare - usually some words are not guessed correctly. In a successful case the reconstructed text looks something like this:
In this example the text was successfully reconstructed adequately. In an unsuccessful case the recreated text may have little - or even nothing - in common with the original. For example, such results are possible:
In this example the guessing was not very accurate. Or even results like these:
In total, the researchers examined about fifteen existing AI-based chatbots and found most of them vulnerable to this attack - the exceptions being Google Gemini (formerly Bard) and GitHub Copilot (not to be confused with Microsoft Copilot).
List of AI-based chatbots examined:
How dangerous is all of this?
It's worth noting that this attack is retrospective. Let's say someone took the trouble to intercept and save your conversations with ChatGPT (which is not so simple but possible) where you discussed some scary secrets with the chatbot. In that case, using the method described above that someone theoretically could read the messages. However, only with a certain probability: as the researchers note they were able to correctly identify the general topic of conversation in 55% of cases. Successfully reconstructing the text happened only in 29% of cases. It's worth clarifying that under the criteria by which researchers evaluated the reconstruction of text as completely successful, a reconstruction like this one falls into that category:
How important such semantic nuances are is for each individual to decide. However, it is worth noting separately that using this method it will likely not be possible to reliably guess factual details (names, numerical values, dates, addresses, contact information and other truly important information). Furthermore, the attack has another limitation that the researchers do not mention: the success of text reconstruction heavily depends on the language in which the intercepted messages were written. The tokenization process operates differently for different languages. For the English language where the effectiveness of this attack was demonstrated, tokens are typically very long - usually equivalent to entire words. Therefore, tokenizing text in English produces distinct patterns making text reconstruction relatively easy. All other languages are much less convenient for this purpose. Even for languages closely related to English in the Germanic and Romance groups the average token length is one and a half to two times shorter, and for Russian it's even two and a half times shorter: a typical "Russian token" is only a couple of characters long likely rendering the attack ineffective. Texts in different languages are tokenized differently. While the attack works for the English language it may not be effective for texts in other languages.
Example of tokenization in different languages by GPT-3.5 and GPT-4 models - English:
Example of tokenization in different languages by GPT-3.5 and GPT-4 models - German:
Example of tokenization in different languages by GPT-3.5 and GPT-4 models - Russian:
At least two AI-chatbot developers: Cloudflare and OpenAI have already responded to the publication of the research and started using the mentioned padding method which is specifically designed to counteract this type of attack. Presumably, other AI-chatbot developers will soon follow suit and in the future interactions with chatbots will likely be protected from this attack.

